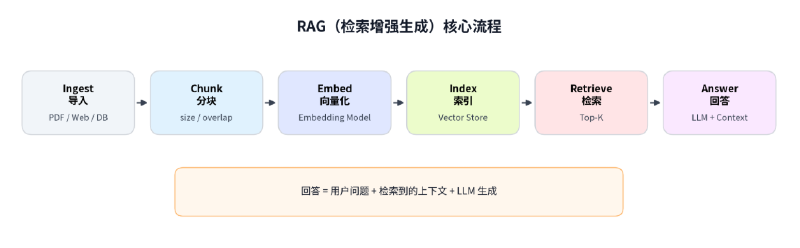
引言
RAG 系统最常见的错觉是:只要答案看起来通顺,就以为检索有效。
但 RAG 的质量不只取决于最后一句回答,而取决于整条链路:
|
|
任何一环出错,最终答案都可能不可靠:
- 检索没找到关键文档
- 找到了但排序太靠后
- 上下文塞入了大量噪声
- 模型没有使用正确证据
- 答案看似合理但不忠于上下文
- 引用指向了错误段落
所以 RAG 评估要回答两个问题:
|
|
前者是检索评估,后者是生成评估。只看其中一个都不够。
RAG 评估的三层结构
一个完整 RAG 评估体系可以分三层。
|
|
第一层:检索评估
检索评估关注:
|
|
它不关心模型最后怎么回答,只看候选文档列表。
第二层:上下文评估
上下文评估关注:
|
|
因为 RAG 通常不是把所有检索结果都塞给模型,中间还会经过重排序、过滤、压缩、拼接。
第三层:答案评估
答案评估关注:
|
|
它要检查正确性、完整性、忠实性和引用准确性。
评估集怎么构建
没有评估集,就没有可重复优化。
RAG 评估集至少包含四部分:
|
|
关键不是只写标准答案,而是写清楚“正确答案应该来自哪些证据”。
样本来源
好的评估集来自真实场景:
- 用户搜索日志
- 客服工单
- 线上失败 case
- 高频业务问题
- 专家人工设计问题
- 文档更新后的回归问题
不要只让 LLM 生成一堆看起来合理的问题。合成问题可以补覆盖面,但核心样本必须来自真实用户。
样本类型
评估集建议覆盖:
| 类型 | 说明 |
|---|---|
| 单跳问题 | 一个文档片段即可回答 |
| 多跳问题 | 需要组合多个片段 |
| 时间敏感问题 | 答案依赖文档版本 |
| 否定问题 | 文档中明确说不支持 |
| 无答案问题 | 知识库没有答案 |
| 相似概念问题 | 容易检索到相近但错误内容 |
| 长尾问题 | 低频但重要 |
RAG 系统最容易在“相似但不相同”的问题上翻车。
检索评估指标
检索阶段的输入是 query,输出是 top-k 文档或 chunk。
Recall@K
Recall@K 衡量正确证据是否出现在前 K 个结果里。
|
|
例如标准证据出现在 top-5,就算 Recall@5 命中。
Recall@K 是 RAG 最重要的基础指标。因为如果正确证据没有被召回,后面的 LLM 再强也只能猜。
Precision@K
Precision@K 衡量前 K 个结果中有多少是相关的。
|
|
Recall 高但 Precision 低,说明系统虽然找到了答案,但也塞了很多噪声。噪声会占用上下文窗口,甚至误导模型。
MRR
MRR(Mean Reciprocal Rank)关注第一个正确结果排在第几位。
|
|
MRR 适合评估“用户希望第一个结果就有用”的场景。
NDCG
NDCG 适合有相关性等级的场景。
例如:
|
|
它不仅看是否命中,还看高相关结果是否排在前面。
Hit Rate
Hit Rate 是最粗粒度指标:
|
|
它简单直观,适合早期快速判断检索是否可用。
上下文评估指标
检索结果通常还要经过重排序、过滤、压缩,最后组装成 context。
这个阶段要评估的是:
|
|
Context Recall
Context Recall 衡量答案所需证据是否都进入了上下文。
如果一个问题需要两个证据:
|
|
但上下文只包含 A,不包含 B,那么 Context Recall 不完整。
多跳问题尤其需要这个指标。
Context Precision
Context Precision 衡量上下文里有多少内容真正有用。
噪声太多会导致:
- token 成本增加
- 模型注意力被稀释
- 错误信息干扰回答
- 引用不准确
一个高质量上下文应该是:
|
|
Context Utilization
Context Utilization 衡量模型最终是否使用了检索到的证据。
有些 RAG 系统虽然检索到了正确文档,但模型回答时没有用,仍然凭内部知识或错误片段回答。
这种情况说明问题不在检索,而在上下文组织或生成提示。
答案评估指标
RAG 最终还是要回答用户问题。
Answer Correctness
答案是否正确。
这个指标可以通过:
- 人工评分
- 标准答案比对
- LLM-as-Judge
- 规则校验
但它不能单独使用。因为一个答案可能正确,但不是基于检索上下文得到的。
Faithfulness
Faithfulness 衡量答案是否忠于上下文。
例如上下文说:
|
|
模型回答:
|
|
这就是不忠实,即使语气再自然也不可信。
Faithfulness 是 RAG 区别于普通问答评估的核心指标。
Answer Relevance
Answer Relevance 衡量回答是否真正回应用户问题。
例如用户问:
|
|
模型回答:
|
|
这可能是事实,但没有回答“多久到账”。
Citation Accuracy
如果系统提供引用,就必须评估引用是否准确。
常见问题:
- 引用了无关 chunk
- 引用位置正确但答案没用它
- 答案有多个事实但只引用一个来源
- 引用文档已过期
引用不是装饰,而是 RAG 可信度的一部分。
Trace:RAG 可观测性的核心
没有 Trace,就很难知道 RAG 为什么错。
一次 RAG 请求至少应该记录:
|
|
有了 Trace,bad case 才能归因。
Trace 需要记录什么
| 阶段 | 关键字段 |
|---|---|
| Query | 原始问题、改写 query、用户上下文 |
| Retrieval | retriever 类型、top-k、score、rank |
| Rerank | reranker 分数、排序变化 |
| Context | chunk 列表、token 数、拼接顺序 |
| Generation | prompt 版本、模型、答案、引用 |
| Feedback | 用户反馈、人工评分、失败原因 |
这些字段不只是为了调试,也是后续评估和优化的数据来源。
Bad Case 归因
RAG 失败要分层定位。
|
|
不同失败原因对应不同修复方式。
| 失败原因 | 修复方向 |
|---|---|
| 检索没召回 | 改 chunk、embedding、hybrid search |
| 排序靠后 | 增加 reranker、调召回路数 |
| 重排序误杀 | 调整 reranker 或保留多路结果 |
| 上下文截断 | 优化上下文预算和压缩策略 |
| 噪声太多 | 提高过滤阈值、做上下文精简 |
| 模型没用证据 | 改生成 prompt、强制引用 |
| 模型幻觉 | 加 faithfulness 检查 |
| 文档过期 | 加文档版本和时效性监控 |
如果只看最终答案,所有错误都会被粗暴归为“模型不行”。这会误导优化方向。
离线评估流程
RAG 离线评估可以按以下流程跑。
|
|
对比实验
每次优化都应该做 A/B 对比:
|
|
比较:
- Recall@5 是否提升
- Precision@5 是否下降
- Faithfulness 是否提升
- 平均 token 是否增加
- 延迟是否可接受
不要只看一个指标。RAG 优化经常是 trade-off:
|
|
线上监控
离线评估不能替代线上监控。
线上需要持续观察:
| 指标 | 说明 |
|---|---|
| No Answer Rate | 系统无法回答比例 |
| User Retry Rate | 用户重复提问比例 |
| Low Confidence Rate | 低置信回答比例 |
| Citation Click Rate | 用户点击引用比例 |
| Retrieval Empty Rate | 检索为空比例 |
| Avg Context Tokens | 平均上下文 token |
| P95 Latency | 95 分位延迟 |
| Cost per Answer | 单次回答成本 |
线上监控的重点是发现分布漂移:
- 用户开始问新问题
- 文档更新后旧答案过期
- 新产品功能没有进入知识库
- 某类 query 的检索突然变差
- embedding 模型升级导致排序变化
RAG 系统不是一次建好就结束,它需要持续维护。
人工反馈闭环
用户反馈和人工标注是 RAG 持续优化的燃料。
每个低分回答都应该沉淀为:
|
|
这样 bad case 才能进入回归集,防止同类问题反复出现。
最小可用评估方案
从零开始可以先做一套最小闭环。
第一步:准备 50 条真实问题
每条问题标注:
- 标准答案
- 标准证据 chunk
- 问题类型
- 是否多跳
- 是否允许无答案
第二步:记录完整 Trace
先不要急着调参数。没有 Trace,优化就是猜。
第三步:先看 Recall@K
如果 Recall@K 很低,优先优化检索,不要调生成 prompt。
第四步:再看 Context Precision
如果 Recall 高但答案差,检查上下文噪声和排序。
第五步:最后看 Faithfulness
如果上下文正确但答案错,说明生成阶段没有忠于证据。
这个顺序很重要:
|
|
常见反模式
只看答案满意度
答案满意度是结果,不是诊断。它告诉你错了,但不告诉你哪里错。
没有标准证据
只有标准答案,没有 golden context,就无法评估检索。
只调 prompt
很多 RAG 问题根本不是 prompt 问题,而是检索没召回或上下文噪声太多。
盲目增大 top-k
top-k 越大,召回可能更高,但噪声也更多。需要配合重排序和上下文压缩。
忽略无答案问题
知识库没有答案时,RAG 应该承认不知道。强行回答会制造幻觉。
小结
RAG 评估的核心不是问“答案看起来好不好”,而是沿着链路逐层追问:
|
|
真正有效的 RAG 系统,一定有三样东西:
- 带标准证据的评估集
- 端到端 Trace
- bad case 回归闭环
没有这些,RAG 优化就只能靠感觉。
有了这些,才能知道“检索真的有效”,也才能把 RAG 从 demo 做成可靠系统。