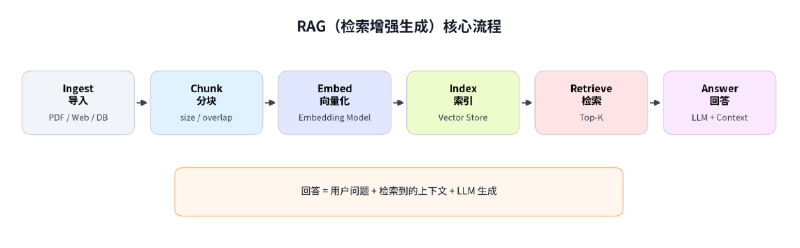
为什么检索是 RAG 的瓶颈
RAG 系统的回答质量取决于 LLM 生成质量,但生成质量的天花板由检索环节决定。检索回来的文档如果不相关,LLM 再强也给不出正确答案——垃圾进,垃圾出。
RAG 的核心瓶颈不是生成,是召回(Recall)。
据统计,企业 RAG 项目失败的案例中,60% 以上根因在检索环节:检索不到、检索不准、检索到的内容噪声太大。本文深入 RAG 检索模块,系统性地梳理向量检索策略和召回优化手段。
基础:文本如何变成向量
嵌入模型(Embedding Model)
嵌入模型将文本映射到高维向量空间。语义相近的文本,向量距离也相近。
|
|
主流嵌入模型选型
| 模型 | 维度 | 最大输入 | 多语言 | 开源 |
|---|---|---|---|---|
| OpenAI text-embedding-3-large | 256~3072 | 8192 token | 一般 | 否 |
| OpenAI text-embedding-3-small | 512~1536 | 8192 token | 一般 | 否 |
| BGE-M3 (BAAI) | 1024 | 8192 token | 优 | 是 |
| Cohere Embed v3 | 1024 | 512 token | 优 | 否 |
| jina-embeddings-v3 | 1024 | 8192 token | 优 | 是 |
| E5-mistral-7b-instruct | 4096 | 32768 token | 良 | 是 |
选型建议:
- 中文为主:BGE-M3 是首选,多语言能力强
- 对维度敏感:OpenAI 支持自定义维度,可平衡精度和效率
- 本地部署:BGE-M3 或 E5 系列
- 长文档:jina-embeddings-v3 或 E5-mistral
相似度度量
检索的本质是在向量空间中找最接近的 top-k 个向量:
余弦相似度(最常用):
|
|
值域 [-1, 1],越接近 1 越相似。对方向敏感,不受向量长度影响。
欧氏距离:
|
|
对向量长度敏感,适合归一化后的向量。
内积(Dot Product):
|
|
适合预归一化的向量(如 OpenAI 嵌入),计算开销最小。
多数向量数据库默认使用余弦相似度,这也是嵌入模型训练时最常用的一致性目标。
基础检索策略
密集检索(Dense Retrieval)
纯向量检索,直接用 query 向量在向量库中做 ANN(近似最近邻)搜索:
|
|
优点:语义理解强,能召回字面不同但意思相同的文档。
缺点:对专有名词、精确 ID、数字等不敏感。比如"订单号 ORD-2024001"这种情况,纯向量检索容易跑偏。
稀疏检索(Sparse Retrieval / BM25)
传统搜索引擎的核心算法,基于词频-逆文档频率(TF-IDF):
|
|
优点:精确关键词匹配,专有名词、编码、数字等场景表现好。
缺点:不懂语义。搜索"怎么连接到数据库"匹配不到"如何建立数据库连接"。
混合检索(Hybrid Search)
密集 + 稀疏 = 互补融合,这是目前工业界的主流方案:
|
|
融合策略:
- RRF(Reciprocal Rank Fusion):
score(d) = Σ 1/(k + rank_i(d)),简单有效,无需调权 - 加权求和:
score(d) = α × dense_score + β × sparse_score,需要调超参数 - 学习融合:用一个小模型学习 dense 和 sparse 的融合权重
RRF 因其无需调参、效果稳定,是目前混合检索最常用的融合策略。
召回优化
查询改写(Query Rewriting)
用户自然的提问方式,和文档的书写风格,往往存在巨大差异。
用户问:“上次那个登录报错的 bug 修好了吗?”
但知识库里的文档写的是:“2026-04-15 修复 auth 模块 session 过期导致 401 的问题”。
直接用原问题检索,大概率召回不到。
解决方案——用 LLM 改写查询:
|
|
查询改写的常见模式:
| 模式 | 做法 | 适用 |
|---|---|---|
| 关键词提取 | LLM 提取关键实体和术语 | 用户问题口语化 |
| 多角度生成 | 从不同角度生成多个查询 | 问题模糊、维度多 |
| 假设文档 | 让 LLM 先生成假想答案,用答案当 query 检索 | 问题复杂需要推理 |
| 逐步细化 | 根据检索结果迭代改写 query | 初检不理想时 |
多路召回(Multi-Channel Recall)
一条检索路径容易漏,多条路径交叉覆盖:
|
|
这个架构是目前生产级 RAG 的标配。多路召回的本质是用冗余换覆盖,用融合算法保证最终结果的质量。
重排序(Re-ranking)
初检的 Top-K 只是"粗排"——向量相似度高不代表真正语义相关。重排序用小模型对初检结果做精排。
|
|
常用 Re-ranker:
| 模型 | 特点 |
|---|---|
| Cohere Rerank v3 | 云服务,效果优秀 |
| BGE-Reranker-v2-m3 | 开源,支持多语言 |
| Cross-Encoder (SBERT) | 经典方案,准确但较慢 |
| LLM as Reranker | 用 LLM 直接打分排序 |
Re-ranker 本质是 Cross-Encoder 架构:将 query 和 document 拼接后送入模型,输出一个 0~1 的相关性分数。比向量余弦相似度更准确,但计算开销大,所以只对初检 Top-K 使用。
重排序的关键权衡:K 越大,精排效果越好,但延迟和成本也越高。经验值 20~50 是一个不错的起点。
分段检索与上下文扩展
检索时只返回匹配的 chunk,但 chunk 前后可能有重要上下文。需要在检索后做上下文扩展:
窗口扩展:返回匹配 chunk + 前后各 N 个 chunk
|
|
句子滑动窗口:以匹配句子为中心,前后各取 M 个句子
父文档检索:检索小 chunk,返回其所属的父文档
这就是 Small-to-Big 策略:用小粒度做检索(避免噪声),用大粒度喂 LLM(保留上下文)。
索引优化
分块策略对检索的影响
分块是 RAG 的"基础工程",分块方式直接决定检索质量:
| 策略 | 做法 | 检索影响 |
|---|---|---|
| 固定 Token 分块 | 每 512/1024 token 切一块 | 简单但容易割裂语义 |
| 递归字符分割 | 按段落→句子→词的优先级切 | 尽量保留自然边界 |
| 语义分块 | LLM 判断分块边界 | 效果最好但成本高 |
| 层级分块 | 父子文档多层索引 | 支持多粒度检索 |
经验分块参数:
- 文档问答:256~512 token
- 技术文档:512~1024 token
- 长文总结:1024~2048 token
- chunk 重叠度:10%~20%
元数据过滤
纯向量检索是在全库中搜索。加上元数据过滤,可以先缩小搜索范围:
|
|
元数据设计原则:
- 记录时间戳(时效性过滤)
- 标注文档类型(分类过滤)
- 保留来源路径(可追溯)
- 添加自定义标签(业务过滤)
层级索引(Hierarchical Index)
对于大型知识库,全库平面检索效率低、精度差。层级索引先定位范围再精细检索:
|
|
适合文档数量 > 10,000 的大规模场景。
高级检索技术
HyDE(Hypothetical Document Embeddings)
用 LLM 先生成假想答案,再用假想答案的向量去检索:
|
|
为什么有效?因为真实文档和"假设答案"往往比和"简短问题"在向量空间中更接近。尤其在问答类场景中效果显著。
代价:多一次 LLM 调用,增加延迟和成本。
自查询检索(Self-Query Retrieval)
让 LLM 从用户问题中提取结构化查询条件 + 语义向量:
|
|
多跳检索(Multi-hop Retrieval)
复杂问题需要多步检索,每一步的结果指导下一步:
|
|
需要 Agent 范式配合——Agent 判断是否需要多跳、何时终止。
查询分解(Query Decomposition)
复杂问题拆解为多个子问题分别检索:
|
|
各子问题检索结果汇总去重后送给 LLM。
检索效果评估
关键指标
| 指标 | 含义 | 目标 |
|---|---|---|
| Recall@K | Top-K 中相关文档占全部相关文档的比例 | 越高越好(>80%) |
| Precision@K | Top-K 中相关文档的比例 | 越高越好 |
| MRR | 第一个相关文档排名的倒数均值 | 越高越好 |
| NDCG@K | 考虑排序位置的归一化指标 | 越高越好(>0.7) |
| Hit Rate | 至少命中一个相关文档的比例 | 越高越好(>90%) |
构建评估集
需要一个"黄金测试集"——(问题, 正确答案/相关文档)对:
- 从历史问答中收集 100~500 个真实问题
- 人工标注每个问题对应的正确答案和应该召回的文档
- 用评估集测试不同检索策略的效果
没有评估集的调优是盲调——你不知道改了参数到底是变好了还是变坏了。
实践:检索优化清单
按优先级排列的调试清单:
- [必做] 检查嵌入模型:模型和语料语言是否匹配?中文用 BGE-M3 通常比 OpenAI 好
- [必做] 检查分块质量:切出来的 chunk 语义完整吗?相邻 chunk 之间有信息断层吗?
- [必做] 上混合检索:密集 + BM25,用 RRF 融合,这个改动通常能带来 10%~20% 的召回提升
- [推荐] 加上重排序:初检 Top-50 + BGE-Reranker 精排 Top-5,对最终答案质量提升显著
- [推荐] 查询改写:如果用户提问偏口语化,加一层 LLM 改写
- [进阶] 多路召回:在混合检索基础上增加改写查询、实体匹配等召回通道
- [进阶] Small-to-Big:小粒度检索 + 父文档上下文扩展
- [高阶] HyDE:问答类场景效果明显,但需评估额外延迟
小结
RAG 的检索优化本质是做减法:从海量文档中筛出最相关的那几条,同时尽可能不遗漏。
核心链路:好的嵌入模型 → 合理的分块 → 混合检索(密集+稀疏)→ 重排序 → 上下文扩展 → 喂给 LLM
在这个链路上,每一个环节都有优化空间,但混合检索 + 重排序是高性价比的组合——一个保证覆盖,一个保证精度。在这套基本功之上,再按实际场景评估是否需要查询改写、多路召回、HyDE 等高级策略。