大模型的四大局限性
以 GPT-4、Claude 为代表的大语言模型(LLM)能力惊艳,但在实际落地中存在几个"先天不足":
1. 知识截止日期
大模型的训练数据有明确的时间窗口。比如 GPT-4 的训练数据截止到 2023 年 12 月,在此之后发生的事情一概不知。你问它"2024 年奥运会金牌榜",它只能编造或拒绝回答。
2. 幻觉问题
大模型本质是概率模型,它不"知道"答案,而是预测最可能的下一个 token。当训练数据中没有足够的相关信息时,模型会"自信地编造"——这就是幻觉(Hallucination)。在法律、医疗等场景下,幻觉可能造成严重后果。
3. 私有知识缺失
企业内部的业务文档、代码库、设计规范等私有数据,从未出现在公开训练语料中。通用大模型对此一无所知,无法直接用于企业内部场景。
4. 上下文窗口限制
即使将私有文档塞进 prompt,大模型的上下文窗口也是有限的。GPT-4 Turbo 支持 128K token,看似很大,但当你面对几千页的企业文档时,仍然杯水车薪。而且长上下文的推理成本、延迟都会线性增长。
这四大痛点催生了一个关键范式:RAG(Retrieval-Augmented Generation,检索增强生成)。
什么是 RAG
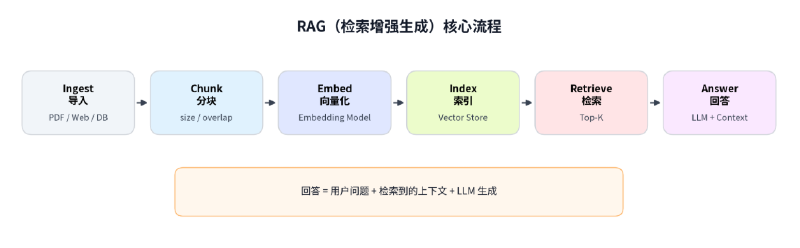
RAG 的核心思想很简单:先检索,再生成。
在用户提出问题后,系统先去外部知识库中检索相关文档片段,然后将检索到的内容连同用户问题一起喂给大模型,让模型基于这些"参考资料"来生成答案。
|
|
这就像考试时允许翻书——大模型不再需要记住所有知识,只需要理解问题并从参考资料中提炼答案即可。
RAG 论文"Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"由 Facebook AI Research(现 Meta AI)于 2020 年提出,论文将 RAG 定义为"将预训练的参数化记忆(大模型)与非参数化记忆(外部知识库)相结合的通用框架"。
RAG 架构详解
一个完整的 RAG 系统通常包含三个核心阶段:
第一阶段:索引(Indexing)
将原始文档处理成可供高效检索的形式。
|
|
文档加载:支持 PDF、Word、网页、Markdown、数据库等多种数据源。
文本分块(Chunking):将长文档切分成适当大小的文本片段。分块策略直接影响检索效果:
| 策略 | 做法 | 适用场景 |
|---|---|---|
| 固定大小 | 按 token 数一刀切 | 通用场景 |
| 语义分割 | 按段落/章节自然边界 | 结构化文档 |
| 滑动窗口 | 重叠切分,保留上下文 | 对上下文敏感的场景 |
| 层级分块 | 父子文档层级索引 | 需要多粒度检索 |
分块大小是核心权衡:太小会丢失上下文,太大会引入噪声。通常 512~1024 token 是一个经验范围。
向量化(Embedding):用嵌入模型将文本片段转成高维向量。语义相近的文本,向量距离也相近。
常用嵌入模型:
| 模型 | 维度 | 特点 |
|---|---|---|
| OpenAI text-embedding-3-large | 3072 | 通用性强,付费 |
| BGE-M3 (BAAI) | 1024 | 多语言,开源 |
| Cohere Embed v3 | 1024 | 企业级,付费 |
| jina-embeddings-v3 | 1024 | 长文本支持 |
向量数据库:存储和检索向量化后的文档。主流选择:
- Chroma:轻量开源,适合原型开发
- Milvus:高性能分布式,适合生产环境
- Pinecone:全托管云服务,零运维
- Weaviate:自带向量化和混合搜索
- Elasticsearch:传统搜索引擎 + 向量检索
第二阶段:检索(Retrieval)
当用户提问时,将问题向量化并在知识库中检索最相关的 k 个文档片段。
检索流程:
|
|
相似度算法:
- 余弦相似度:最常用,计算向量夹角
- 欧氏距离:适合低维向量
- 内积:适合归一化向量
检索策略优化:
基础的向量检索在实际应用中常常不够,需要多种增强手段:
- 混合检索(Hybrid Search):向量检索 + 关键词检索(BM25)结合,兼顾语义和精确匹配
- 重排序(Re-ranking):初检后用小模型对结果二次排序,提升 Top-K 精准度
- 查询改写(Query Rewriting):用 LLM 将用户问题重写为更利于检索的形式
- 多轮检索(Multi-hop):复杂问题拆分多步,逐步检索和推理
第三阶段:生成(Generation)
将检索到的文档片段与用户问题组装成 prompt,交由 LLM 生成最终答案。
一个典型的 RAG prompt 模板:
|
|
关键点:
- 明确指示"无法回答时如实说明",降低幻觉
- 引用来源,让答案可追溯
- 控制 prompt 长度,避免超出模型上下文窗口
RAG 的进阶架构
基础 RAG 能解决简单问答,但面对复杂场景时力不从心。业内发展出几种进阶架构:
Modular RAG
将 RAG 的索引、检索、生成三阶段进一步拆分为可替换的模块。不同场景使用不同的检索器、生成器组合,灵活度高。
Graph RAG
用知识图谱替代向量库作为外部知识。适合实体关系复杂、需要多跳推理的场景。微软开源的 GraphRAG 是该方向的代表实现。
Agentic RAG
将 RAG 与 AI Agent 结合。Agent 自主决定何时检索、检索什么、是否需要重新检索、是否需要拆分子问题。Agentic RAG 是 RAG 从"被动回答"到"主动推理"的进化方向。
Self-RAG
让 LLM 在生成过程中自我评估是否需要检索,以及检索结果是否相关。通过特殊的"反思 token"训练模型具备检索判断能力。
RAG 的应用场景
1. 企业知识库问答
最典型的 RAG 落地场景。将企业内部的规章制度、技术文档、产品手册、会议纪要等导入知识库,员工用自然语言提问即可获得答案。
优势:
- 新员工入职可快速上手
- 打破部门信息壁垒
- 降低老员工答疑成本
2. 智能客服
将产品文档、FAQ、历史工单导入 RAG 系统,替代传统的关键词匹配客服。能理解用户复杂问题,给出针对性解答。
3. 代码助手
对代码库建立索引,开发者直接用自然语言询问:“这个项目的鉴权逻辑在哪?““如何添加一个新的 API 接口?”
与直接依赖 LLM 训练数据中的代码知识不同,RAG 让 AI 真正"理解"当前项目的代码。这个思路也是当下 AI 编程工具(如 Claude Code、Cursor、Copilot 的 codebase 检索)的核心能力。
4. 法律/医疗辅助
导入法规条文和判例,辅助律师快速查找相关法律依据。导入医学文献和临床指南,辅助医生获取循证建议。这两个领域对准确性要求极高,必须有来源引用来降低幻觉风险。
5. 学术研究
研究人员将论文 PDF 导入知识库,用 RAG 快速梳理文献、发现跨领域关联、生成文献综述初稿。
6. 多模态 RAG
不仅检索文本,还能检索图片、表格、音视频。比如上传一张设备故障的照片,系统检索维修手册中的相关章节并给出修理建议。
RAG 的挑战
RAG 并非银弹,实际落地面临不少挑战:
| 挑战 | 说明 |
|---|---|
| 文档解析 | PDF 表格、扫描件、复杂排版的解析效果参差不齐 |
| 分块策略 | 一刀切容易割裂语义,自动化语义分块不够成熟 |
| 检索质量 | 高维向量空间的"语义漂移"导致检索结果不相关 |
| 生成质量 | 检索到不相关文档可能误导 LLM |
| 评估困难 | 缺乏统一的 RAG 系统评估标准 |
| 延迟 | 嵌入+检索+LLM 生成,端到端延迟可能难以接受 |
| 数据更新 | 知识库如何增量更新,无需全量重建索引 |
RAG 技术栈一览
|
|
小结
RAG 解决了大模型在落地中的三个核心矛盾:
- 知识的时效性与静态训练的矛盾——RAG 随时更新知识库
- 知识的广度与私有化需求的矛盾——RAG 接入企业私有数据
- 知识的准确性与概率输出的矛盾——RAG 用参考资料约束幻觉
随着 Agentic RAG、Graph RAG 等进阶架构的成熟,RAG 正在从"带检索的问答系统"进化为"具备推理能力的企业知识中枢”。