
redis中的list和java中的linkedlist类似,是一种线性有序结构,按照元素被推入列表中的顺序存储元素,满足先进先出的需求。可以把它当作队列、栈来使用。
内部结构演进
linkedlist
在redis3.2之前List底层数据结构由linkedlist或者ziplist实现,优先使用ziplist存储。当List对象满足以下两个条件时,将使用ziplist存储,否则使用linkedlist。
-
链表中的每个元素占用的字节数小于64
-
链表中的元素数量小于512个
关键源码:
|
|
redis链表的特性
-
双端:链表节点带有prev和next指针,获取某个节点的前置和后置节点的时间复杂度都是O(1)
-
无环:链表头节点的prev和尾节点的next指针指向的都是null。对链表的访问以null结尾。
-
带表头指针和表尾指针:list结构体有head和tail指针,获取链表头尾节点的时间复杂度为O(1)
-
len属性:list结构体有len属性,获取节点数量的时间复杂度为O(1)
ziplist
linkedlist中存在prev、next两个指针,在数据很小的情况下,指针占用的空间会超过数据占用的空间。
linkedlist是链表结构,在内存中不是连续的,遍历效率低下。
为了解决上述的两个问题,创建了ziplist,ziplist是一种内存紧凑的数据结构,占用一块连续的内存空间,能够提高内存利用率。
当一个Lists只有少量数据,并且每个列表项要么是小整数型,要么是比较短的字符串时,就会使用ziplist来作为List的底层数据结构存储数据。
ziplist是一块连续的内存,结构如下:
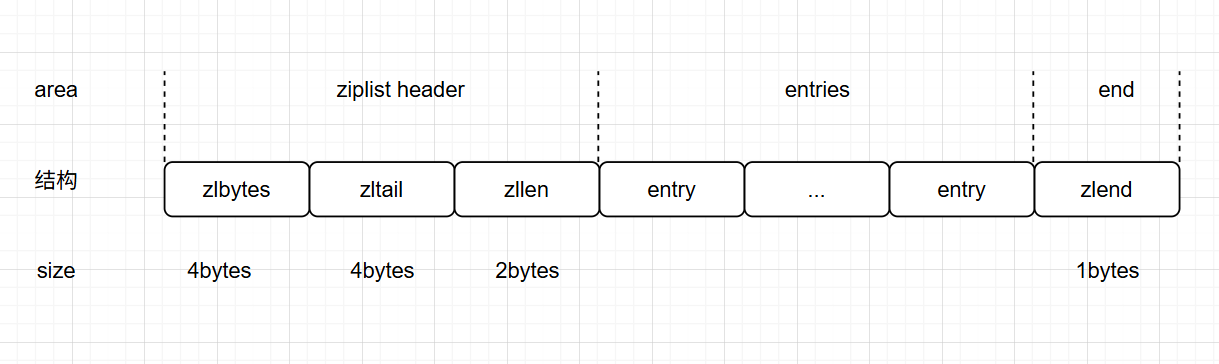
-
zlbytes:占用4字节,记录整个ziplist占用的总字节数
-
zltail:占用4字节,只想最后一个entry偏移量,用于快速定位最后一个entry
-
zllen:占用2字节,记录entry总数
-
entry:Lists的元素
-
zlend:ziplist结束的标志,占用1字节,值等于255
因为ziplist头尾元数据大小是固定的,并且zllen记录了ziplist头部最后一个元素的位置,所以可以用O(1)的时间复杂度找到ziplist中第一个或最后一个元素。而在查找中间元素时,只能从Lists头部或尾部开始遍历,时间复杂度O(n)。
存储数据的entry结构如图所示:
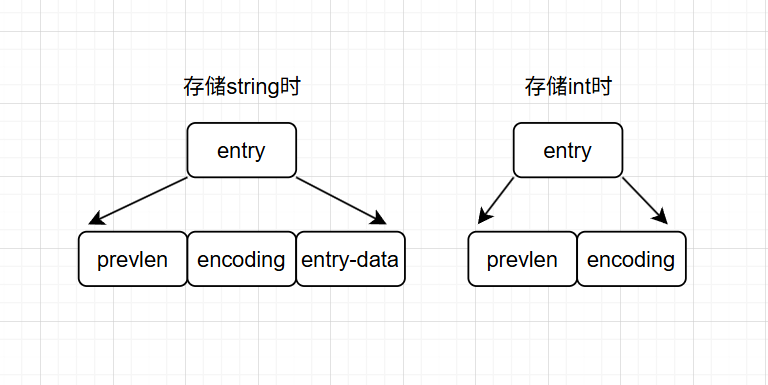
-
prevlen:记录前一个entry占用的字节数,逆序遍历就是通过这个字段确定的向前移动多少字节拿到上一个entry的
首地址的。这部分会根据上一个entry的长度进行变长编码。变长方式如下:-
前一个entry的字节数小于254(255用于zlend),prevlen的长度为1字节,值等于上一个entry的长度。
-
前一个entry的字节数大于等于254,prevlen占用5字节,第一字节配置为254作为一个标识,后面4字节组成一个32位int值,用于存放上一个entry的字节长度。
-
-
encoding:表示当前entry的类型和长度,前两位用于表示类型,前两位为11时表示存储的是int类型,其他情况表示存储的字符串。
-
entry-data:实际存放数据的地方,但是当entry存储的是int类型时,encoding和entry-data会合并到encoding中,并没有entry-data字段。
linkedlist与ziplist对比
为什么说ziplist节省内存?
-
与linkedlist相比,少了prev和next指针。
-
通过encoding字段针对编码进行细化存储,尽可能做到按需分配。
ziplist的不足:
-
不能保存过多的元素,否则查询性能下降,导致O(n)时间复杂度。
-
ziplist存储空间是连续的,当插入新的entry时,内存空间不足就需要重新分配一块连续的内存空间,引发连锁更新。
连锁更新问题:
每个entry都用prevlen记录上一个entry的长度,在当前entry B 前面插入一个新的entry A 时,会导致 B 的prevlen发生变化,也会导致 B 的大小发生改变。同理后面的entry C 也会发生改变。以此类推,就可能导致连锁更新问题。
连锁更新会导致多次重新分配ziplist的存储空间,直接影响ziplist的查询性能。所以在redis3.2引入了quicklist。
quicklist
quicklist结合了linkedlist与ziplist的优势,本质还是一个双向链表,只不过链表的每一个节点都是一个ziplist。
结构体源码如下:
|
|
quicklist是ziplist的升级版,优化的关键点在于控制好每个ziplist的大小或者元素个数。
但是存在两个极端情况:
-
quicklist node的ziplist越小,可能造成越多的内存碎片。极端情况是每个ziplist只有一个entry,退化成了linkedlist。
-
quicklist node的ziplist过大,极端情况下会造成一个quicklist只有一个ziplist, 退化成了ziplist, 连锁更新的问题就会暴露出来。
所以在5.0版本的时候设计了另一个数据结构listpack, 并在7.0版本中替换掉了ziplist。
listpack
listpack的结构如图所示:
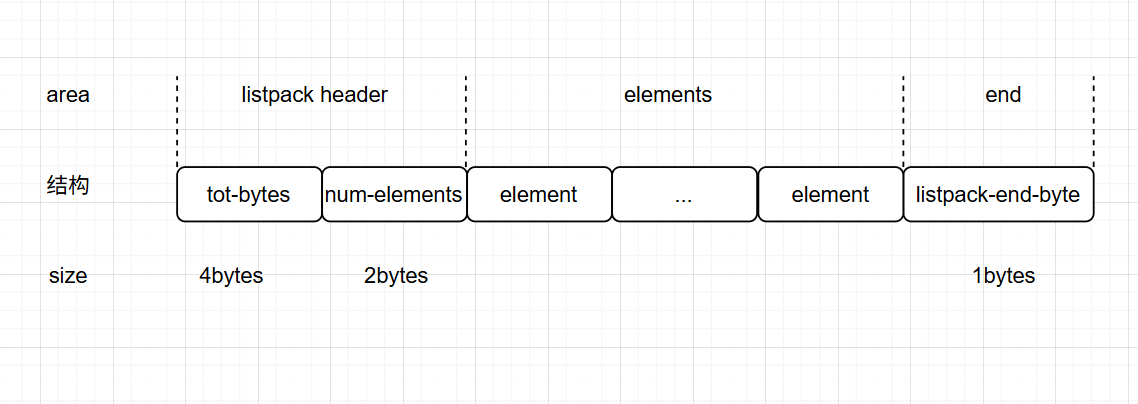
-
tot-bytes:即total bytes,占用4字节,记录listpack占用的总字节数
-
num-elements:占用2字节,记录listpack elements的个数
-
elements:listpack元素,保存数据的部分
-
listpack-end-byte:结束标志,占用1字节,固定值为255
element结构如图所示:
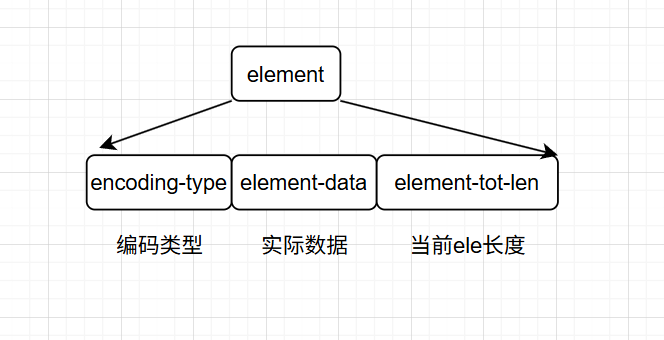
-
encoding-type:存储实际数据的编码类型和长度,是一个变长字段。
-
element-data:存放实际数据。
-
element-tot-len:前两个字段的总长度,不包括自身长度。
每个element只记录自身长度,修改或新增元素时,不会影响后续element的长度,解决了连锁更新的问题。
消息队列实战
消息队列介绍
消息队列是一种异步的服务间通信方式,适合用于分布式和微服务架构。消息在未被处理和删除之前一直在队列上。
消息队列基于先进先出(FIFO)的设计原则,允许发送者(生产者)向队列中发送消息,而接收者(消费者)则可以从队列中获取消息进行处理。通常消息队列被用于解耦应用程序的各个组件,实现异步通信、削峰填谷、解耦合、流量控制等。
消息队列特性:
-
消息有序性:消息是异步处理的,但消费者需要按生产者发送消息的顺序来消费,避免出现后发送的消息被先处理的情况。
-
重复消息处理:当网络问题出现消息重传时,消费者可能收到多条重复消息,可能造成同一业务逻辑被多次执行。在这种情况下,应用系统需要确保幂等性。
-
可靠性:保证一次性传递消息。如果发送消息时接收者不可用,消息队列会保留消息,直到成功传递它,消费者重启后可以继续读取消息进行处理,防止消息遗漏。
redis实现
实时消费问题
生产者可以使用LPUSH key element[element…] 的形式将消息插入队列头部,如果key不存在则会创建一个空的队列再插入消息。
消费者可以通过RPOP key 的形式依次读取队列的消息,以此实现先进先出的消息队列。
但是LPUSH、RPOP存在性能风险,生产者向队列插入消息时,Lists并不会主动通知消费者及时消费。程序需要不断轮询并判断是否为空再执行消费逻辑,这就会导致即使没有新的信息写入,消费者也在不停的调用RPOP命令占用CPU资源。
redis提供了BLPOP、BRPOP的阻塞读取的命令,消费者在读取队列没有数据时会自动阻塞,直到有新的消息写入队列,才继续读取新消息执行业务逻辑。
重复消费解决方案
-
消息队列自动为每一条消息生成一个全局ID
-
生产者为每条消息创建一个全局ID,消费者把处理过的消息ID记录下来,判断是否重复
其实这就是密等,对于同一条消息,消费者收到后处理一次的结果和处理多次的结果是一样的。
消息可靠性解决方案
场景:消费者读取消息处理过程中宕机了,就会导致消息没有处理完成,可是数据已经不在队列中了。
这种现象的本质是消费者处理消息时崩溃了,无法再读取消息,缺乏一个消息确认的可靠机制。
redis提供了BRPOPLPUSH source destination timeout 命令,含义是以阻塞的方式从source队列读取消息,同时把这个消息复制到另一个destination队列中(备份),并且是原子操作。
不过这个命令在redis6.2版本被BLMOVE取代。
BLMOVE op1 op2 RIGHT LEFT 0
消费者在消费时在while循环中使用BLMOVE,以阻塞的方式从队列 op1 队尾消费消息,同时把消息复制到队列 op2 队头(备份队列),该操作是原子性的,最后一个参数 timeout=0 表示持续等待。
如果上述命令消费成功,就使用 LREM 命令把队列 op2 中的对应消息删除,从而实现 ACK 确认机制。如果消费异常,使用 BRPOP op2 从备份队列中再次读取消息即可。