
存储引擎的数据结构
存储引擎要做的事情是将磁盘的数据读取到内存并返回给应用,或者将由应用更改的数据从内存写入磁盘。目前大多数流行的存储引擎都是基于B-Tree或LSM(Log Structured Merge)-Tree这两种数据结构设计的。
Oracle、SQL Server、MySql(InnoDB)和PostgreSQL等传统型关系型数据库依赖的底层存储引擎都是基于B-Tree开发的;而ElasticSearch(Lucene)、Apache HBase、LevelDB和RocksDB等NoSQL数据库存储引擎都是基于LSM-Tree开发的。当然有些数据库采用了插件式的存储引擎架构,实现了Server层和存储引擎层的解耦,可以支持多种存储引擎,如MySQL既可以支持B-Tree数据结构的InnoDB存储引擎,又可以支持LSM-Tree数据结构的RocksDB存储引擎。
对于MongoDB来说,也采用了插件式存储引擎架构,底层的WiredTiger存储引擎可以支持B-Tree和LSM-Tree两种数据结构组织数据,但MongoDB在使用WiredTiger作为存储引擎时,目前默认的配置是使用B-Tree数据结构。
磁盘中的基础数据结构
对于WiredTiger存储引擎来说,集合所在的数据文件和相应的索引文件都是按B-Tree数据结构来组织的,不同之处在于 数据文件 对应的B-Tree叶子节点上除了存储键名(key)外,还会存储真正的集合数据(value),所以数据文件的存储结构也可以被认为是一种B+Tree结构。结构如下图所示。
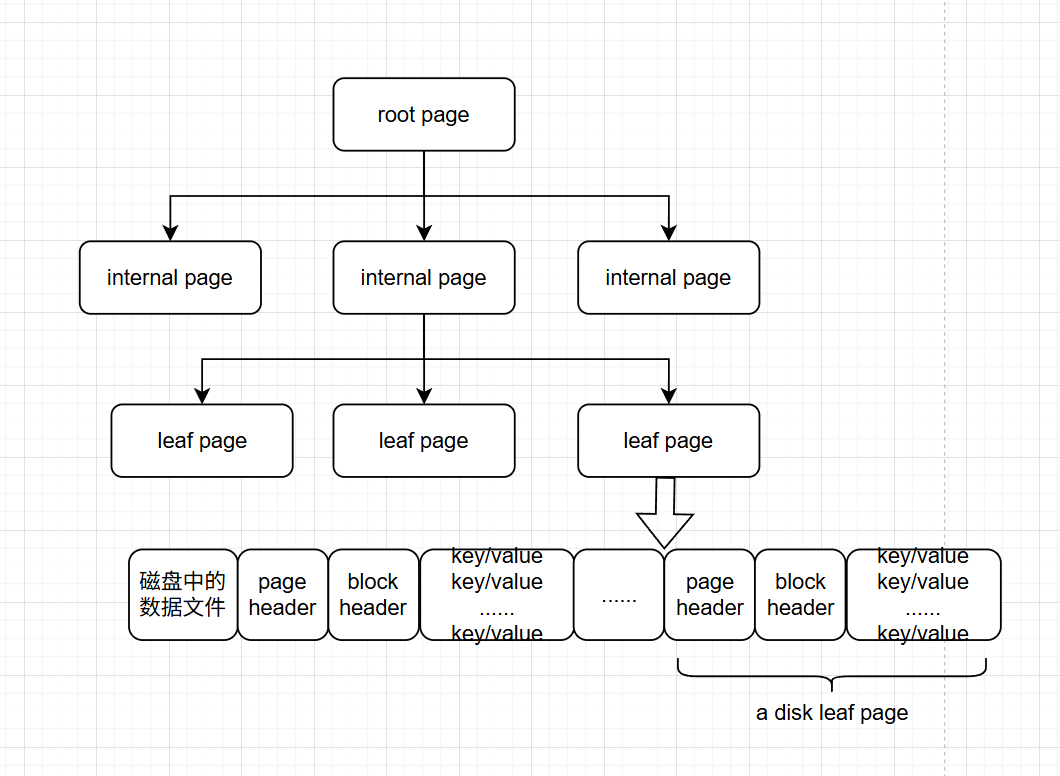
从图中我们可以看出,B+Tree结构中的leaf page包含一个页头、块头和真正的数据。其中,页头定义了页的类型、页中实际存储数据的大小、页中记录条数等信息;块头定义了此页的checknum、块在磁盘上的寻址位置等信息。
内存中的基础数据结构
WiredTiger会按需求将磁盘中的数据以page为单位加载到内存,同时在内存中会构造相应的B-Tree结构来存储这些数据。为了更高效的支撑CRUD等操作以及将内存中的数据持久化到磁盘,WiredTiger也会在内存中维护其他的数据结构。
-
内存中的B-Tree结构包含3种类型的page,即root page、internal page和leaf page。前两者包含指向其子页的page index指针,不包含真正的数据,leaf page包含集合中的真正数据和指向父页的指针。
-
内存中的leaf page会维护一个
WT_ROW的数组变量,将保存从磁盘leaf page读取的key/value值,每一条记录都有一个cell_offset的变量,表示这条记录在page上的偏移量。 -
内存中的leaf page会维护一个
WT_UPDATE结构的数组变量,每条被修改的记录都会有一个数组元素与之对应,如果某条记录被多次修改,则会将修改值以链表形式保存。 -
内存中的leaf page会维护一个
WT_INSERT_HEAD结构的数组变量,具体插入的data会保存在WT_INSERT_HEAD结构的WT_UPDATE属性上,且通过key属性的offset和size可以计算出此条记录要插入的位置;同时,为了提高寻找插入位置的效率,每个WT_INSERT_HEAD结构的数组变量以跳转链表的形式构成。
page的其他数据结构
-
WT_PAGE_MODIFY:用于保存page上事务、脏数据字节大小等与page修改相关的信息。
-
WT_PAGE_LOOKASIDE:当对一个page进行reconclie(写入磁盘)时,如果系统中还有之前的读操作正在访问此page中修改的数据,则会将这些数据保存到lookaside table中。当再次读page时,可以利用lookaside table中的数据重新构建内存page。
-
WT_ADDR:当page被成功reconclied后,对应的磁盘上块的地址,会按照这个地址将page写入磁盘,块是磁盘上文件的最小分配单元,一个page可能有多个块。
-
checksum:page的校验和,如果page从磁盘读到内存上之后没有任何修改,比较checksum可以得到相同的结果,后续reconclie时此page不必再写入磁盘。
page eviction——页面淘汰
当内存中的脏页达到一定比例或内存使用量达到一定比列时,就会触发相应的evict page线程将page按一定的算法淘汰(LRU队列),以便有足够的空间,从而保障后续的插入和修改操作。
-
当内存使用量达到eviction_target设定值时(默认配置为80%),会触发
后台线程执行page eviction;如果内存使用量继续增长,达到eviction_trigger设定值时(默认90%),则应用线程支撑的读写操作等请求被阻塞,应用线程也参与到页面淘汰中,以加速淘汰内存中的page。 -
当内存中的脏数据达到eviction_dirty_target设定值时(默认5%),会触发
后台线程执行page eviction;如果脏数据继续增长,达到eviction_dirty_trigger设定值(默认20%)时,则会同时触发应用线程来执行page eviction。
特殊情况:当在page上不断进行插入或更新操作时,如果page中的内容占用内存的空间大于系统设定的最大值,则会强制触发page eviction。首先将大page拆分成多个小page,再通过reconcile将这些小的page保存到磁盘上,一旦reconcile写入磁盘的操作完成,这些page就能从内存中淘汰出去,从而为后面的操作保留足够的空间。
page reconcile——数据写入磁盘
WiredTiger实现了一个reconcile模块来完成将内存中的修改的数据生成相应的磁盘映像(与磁盘中的page格式匹配),再将这些磁盘映像写入磁盘的操作。
将内存leaf page中的新插入和修改的数据写入磁盘流程如下:
-
首先,内存中的leaf page中修改的插入的数据分别会保存在WT_UPDATE和WT_INSERT_HEAD数组中。
-
然后,创建一个buffer(缓存),为其分配一个磁盘page大小的内存,遍历leaf page中所有插入数组和修改数组上的key/value,将这些数据依次复制到buffer中并进行排序。
-
如果数据所占内存不超过一个磁盘page的大小,则会直接将这些数据写入一页磁盘映像中,再写入磁盘。
-
如果数据超过一个磁盘page,则会将数据分为多个磁盘映像,然后将所有的磁盘映像写入磁盘。
Cache的分配规则
WiredTiger启动时会向操作系统申请一部分内存以供自己使用,这部分内存被称为Internal Cache。如果在主机上只运行MongoDB相关的服务进程,则剩余的内存可以作为文件系统的缓存(File System Cache)并由操作系统负责管理。
当MongoDB启动时,首先从整个主机内存中切出一大块来分给WiredTiger的Internal Cache,以用于构建B-Tree中的各种page,以执行基于这些page的增加、删除、修改、查询等操作。
然后,从主机内存中再额外划分出一部分内存容量以供MongoDB创建索引专用,默认最大值500MB。
最后,将主机的剩余内存容量作为文件系统缓存,供MongoDB使用,这样,MongoDB可以将压缩的文件也缓存到内存中,从而减少磁盘IO次数。
为了节省磁盘空间,集合和索引在磁盘中的数据是被压缩的,在默认情况下,集合采取的是块压缩算法,索引采取的是前缀压缩算法。
事务
MongoDB3.0版本引入WiredTiger存储引擎之后开始支持事务,3.6之前的版本只能支持单文档事务,从4.0开始支持复制集部署模式下的事务,从4.2开始支持分片集群中的事务。
MongoDB的所有事务都在一个sesion中,且一个session可以包含多个事务。
事务的基本原理
与关系型数据库一样,MongoDB事务同样具有ACID特性。
-
原子性(Automicity):一个事务要么完全执行成功,要么不做任何改变。
-
一致性(Consistency):当多个事务并行时,元素的属性在每个事务中保持一致。
-
隔离性(Isolation):当多个事务同时执行时,互不影响。WiredTiger提供了三种隔离级别,读未提交、读已提交和快照,MongoDB默认选择的是快照隔离级别。
-
持久性(Durability):一旦事务提交,数据的更改就不会丢失。
在不同的隔离级别下,一个事务的生命周期内,允许出现的数据范围不一样,可能会出现脏读、不可重复读、幻读等现象。
- 脏读
事务A读取到了事务B还未提交的数据。
- 不可重复读
事务A前后两次读取同一记录的值不一样。
- 幻读
事务A前后两次读取的数据集不一样(条数不一样)。
每种隔离级别现象分析:
-
读未提交(read-uncommitted):A事务运行过程中能看到B事务修改但未提交的数据,因此可能出现脏读、不可重复读、幻读。
-
读已提交(read-committed):A事务运行过程中能看到B事务修改且提交过的数据,可以避免脏读,但不能避免不可重复读和幻读。
-
快照隔离(snapshot):A事务运行过程中能看到A事务开始之前且已经提交的其他事务的数据和A事务开始时其他未提交的事务的修改的数据,A事务开始之后其他事务再提交的修改数据是看不到的。快照隔离不会出现脏读和不可重复读,但可能会出现幻读。
事务的snapshot隔离
MongoDB启动时默认选择的是snapshot隔离级别。事务开始时,会创建一个快照,从已提交的事务中获取行版本数据,如果行版本数据标识的事务尚未提交,则从更早的事务中获取已提交的行版本数据作为其事务开始时的值。
通过事务可以看到其他还未提交的事务修改的行版本数据,但不会看到事务id大于snap_max的事务修改的数据。
MVCC并发控制机制
要实现事务之间的并发操作,可以使用锁机制和MVCC控制等。对于WiredTiger来说,使用MVCC控制来实现并发操作,相较于锁机制的并发,MVCC是一种乐观并发机制,因此它比较轻量级。
MVCC是在内存中维护一个多版本的行数据的,也就是说它会将多个写操作,针对同一行记录的修改以不同行版本号的形式保存下来,从而实现事务的并发操作。
示例如下:
-
A事务首先从表中读取要修改的行数据,读取的库存值为100,行记录的版本号是1。
-
B事务也从中读取要修改的相同行数据,读取的库存值是100,行记录的版本号是1。
-
A事务修改库存值后提交,同时记录行版本号加1,变为2,大于A事务一开始读取的版本号,A事务可以提交。
-
但B事务提交时发现此时行记录版本号为2,产生冲突,B事务提交失败。
-
B事务尝试重新提交,此时再次读取的版本号为2,再加1后为3,不会产生冲突,B事务正常提交。
事务日志(Journal)
Journal是一种WAL(Write Ahead Log)事务日志,目的是实现事务提交层面的数据持久化。
Journal持久化的对象不是修改的数据,而是修改的动作,以日志的形式先保存到事务日志缓存中,再根据相应的配置按照一定的周期,将缓存中的日志数据写入日志文件中。
完整的写操作流程
-
在一个session中开启一个事务,同时构造一个snapshot的结构,作为本次事务执行过程中能够看到的快照数据。
-
将写操作相关的事务日志写入日志缓存中,再提交事务,如果发生错误则回滚事务;事务日志按照设定的规则持续从内存刷新到磁盘。
-
写操作修改的数据在缓存中以特定的数据结构被保存起来。
-
当缓存中的内存使用量或脏数据达到一定条件时,会触发页面淘汰动作,从淘汰队列中按优先级选取包含修改数据的内存page写入相应的磁盘page中。同时,在这个过程中,会先通过reconcile线程将修改的数据构造成磁盘映像格式,再写入磁盘,然后,删除内存脏页以释放占用的内存。
-
当真正的数据page从内存写入磁盘上时,会调用WiredTiger的block management模块提供的接口完成,同时压缩数据。