
前言
原生map设计的缺陷
-
不支持并发,需要加锁操作,原生库提供的有sync.map,底层存储所使用的容器还是map。
-
不会自动缩容。内置的map有自动扩容的功能,但是当删除大量数据之后不会自动缩容,删除之后桶本身占用的内存并不会被回收。(可以通过定时新建map拷贝来实现,但是比较麻烦)
-
如果存放的数据的类型是指针时,GC会扫描map的所有元素,效率不高。
三方库主流解决方案
-
三方库通过
预分配内存(创建时指定map大小,当插入时如果没有空位就通过淘汰算法清除老数据)+分片hash(将一个大map拆分成多个小map,分片减少了key进入同一个hash shard的概率,同时,当一个分片加锁时不会影响别的分片)+缓存淘汰算法(lfu、lru、fifo等)通过控制数量来减少map不缩容带来的影响。 -
也有三方库底层通过map+slice的形式来减少不缩容的影响,其中slice用来真正的存储value,map[key][index]用来查找key在slice中对应的下标。
三方库对比
bigcache
存储结构
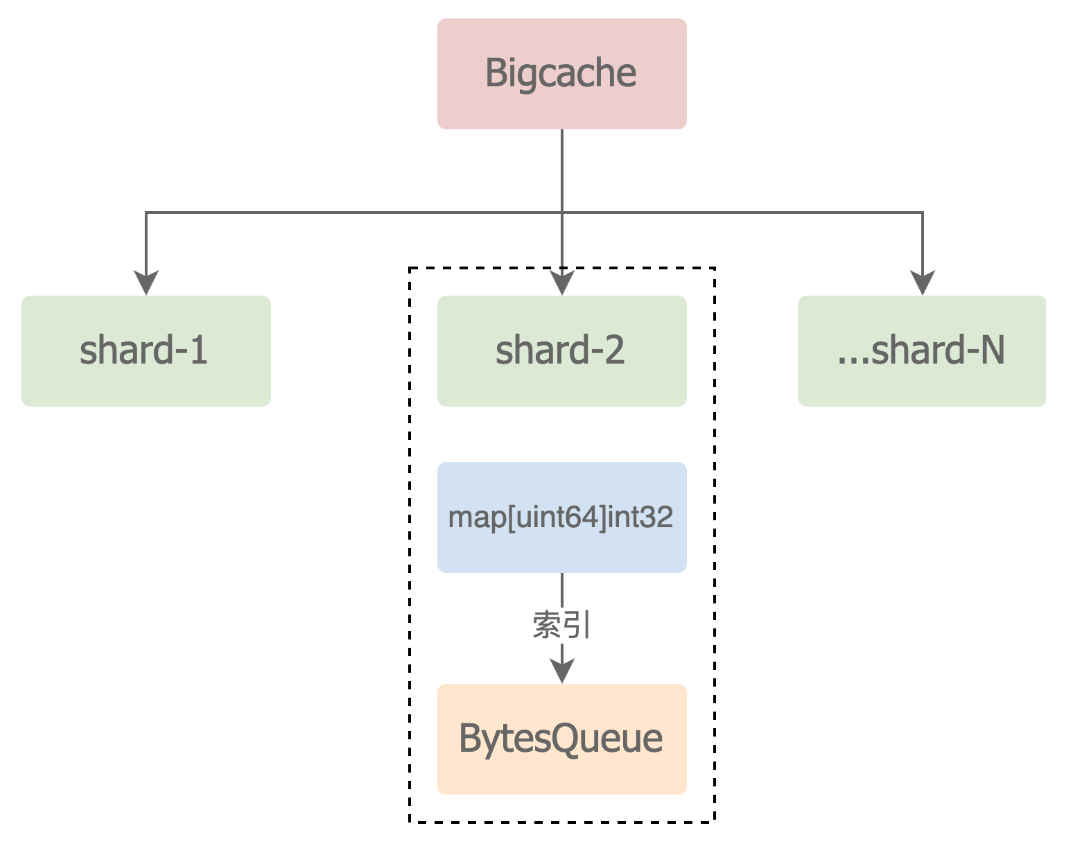
分片hash+[]byte ,每一个分片称为一个shard(map[int64]int32,避免了存储指针),在get或者set时会先对key进行hash,根据hash值判断操作哪一个shard,之后的操作都是在shard上进行的。(shard之间互不影响,每个都有读写锁)真正的item(set的value)是存储在[]byte(bytesqueue,gc对于切片当作一个变量扫描,无需遍历整个数组)中的,分片(shard)中的value其实就是该item对应的下标。
添加操作
添加操作分为三种情况:
-
要添加的key已经存在(也可能是hash碰撞):由于使用的是FIFO淘汰策略,所以即使有旧值的情况下,新值也不会复用其内存,而是push新的value到队列中。之前的旧值并未从内存中移除,仅将其偏移量从hashmap中移除,使得外部读不到。
旧值何时淘汰:
-
设置了CleanWindow,且旧值刚好过时,会被清理器自动淘汰。
-
设置了MaxEntrySize或者HardMaxCacheSize,当内存满时,也会出发旧数据的淘汰。
-
|
|
-
bytesqueue已满:
a. 如果bytesqueue未达到设定的HardMaxCacheSize上限,或者HardMaxCacheSize没有设置,则直接扩容直到切片上限。
b. 如果已达上限,则会删除最旧的数据(无论是否过期),知道可以将当前数据添加进去。
-
正常情况下,加当前shard的写锁,直接添加并更新索引。
获取操作
添加操作的逆过程。需要注意的是,如果获取时数据到达了过期时间,但还没有被清理掉,这时也是可以成功获取到的。是符合大多数需求场景的。
删除操作
和添加时清除旧值类似。
淘汰策略
采用FIFO淘汰策略。新增数据,以及对老数据进行修改,都是直接append到[]byte(bytesqueue)中的。基本不对内存进行修改删除。同时,每个数据项不能单独设置缓存时长,必须全部保持一致。这样对数据淘汰比较友好。
freecache
存储结构
freecache和bigcache类似,也是分片的思想。freecache内部包含256个分段(segment),每个分段都有一把锁。每个分段内部包含两个指针rb(ringbuffer,底层是切片,存储真实数据)和slotsData(也是切片,存储数据在rb中的下标,查找时二分法遍历)。指针固定512(rb和slotData)个,所以号称0GC。但是freecache的key和value都是[]byte类型的。需要进行序列化操作。
添加操作
先对key进行hash,低8位对应segment数组,低8-15位选取slot下标, 同时取高 16 位做 hash16 用于 slot 内快速比较。 然后通过二分法寻找小于等于当前hash16,如果找到等于的还要继续对比key的信息。如果找到相同的key,则是更新操作,没找到就是插入。更新时会比较新value和老value的大小,如果比老的小就可以直接覆盖写入,否则就在rb的末尾寻找空间写入。插入时如果rb空间不足就会触发淘汰机制。
查找操作
与添加操作的查找类似,先通过key定位segment,然后继续定位slot,然后根据hash16进行二分查找。如果找到了继续对存储的key进行对比。完全命中才算。命中时读取其设置的过期时间,如果已经到了,返回未命中,并将此项标记为删除。没过期就更新相关的命中统计。
删除操作
value的定位和上面的一样,找到之后会将索引从slot中移除, 并把该 entry 的 header 标记 deleted = true(逻辑删除标识,写在 header 里)。这意味着索引已经不再指向该条目,外部 Get/Set 不会再找到它。
淘汰机制
当 RingBuf 空间不足时,FreeCache 会从缓冲区的头部开始主动淘汰数据以释放空间。其淘汰策略是一个精巧的、近似 LRU 的策略,综合考虑了访问时间和过期时间。 freecache 不是精确维护一个 LRU 链表,而是用分段 + 环形缓冲 + “平均访问时间”比较的方法:当某个段要腾空间时,优先删除过期或“比段平均访问时间更旧(更冷)”的条目;如果条目相对较新(热),则把它搬到环形缓冲的尾部以保留。这个策略因此被称为 Nearly LRU(近似 LRU)。
ristretto
存储结构
与前面的框架类似,也是分片hash的设计思想(256个分片+读写锁)(最底层使用的map存储的value),但是最底层存储的key是经过计算后的hash值(该框架对key计算了两个hash值<两个uint64>,keyhash和 conflict ,后者用于判断冲突,使用的是xxhash算法)。该框架在初始化实例时会自动启动一个协程processItems来进行增删改的操作,并周期性的进行GC回收。
添加操作
-
首先会检查设置的过期时间,如果小于0直接返回false代表失败,为0表示永不过期。然后根据key计算出两个hash值。然后会先尝试更新操作,如果返回更新成功,会直接修改存储的value,并将当前item的flag修改为更新操作。然后尝试将这个item放入到setbuff的缓冲队列中(channel),如果队列未满或者满了但是当前操作是更新会返回true,视为写入成功,否则返回false并记录指标。然后processItems协程会从setbuff中获取数据(select)。
-
获取到数据之后,首先会判断当前item是否是特殊item(内置一个空结构体类型的channel字段wait), 由于是协程监听进行的增删改操作,不保证强一致性,Ristretto提供了一个Wait函数来等待之前设置的item全部设置成功,该函数会进行阻塞(读取wait),直到setbuff执行到这个特殊的item,然后关闭这个特殊item的wait,结束Wait函数,表示数据已经完全录入完毕。
-
如果是普通的item,会先计算这个item的消耗cost,如果初始化时提供了Coster函数,并且当前flag不是删除,且item的cost为0,就会调用提供的函数进行计算真实的cost,然后还会加上内部存储占用 itemSize,除非在 Config 中设置 IgnoreInternalCost = true。
-
然后判断当前item的flag是否是添加操作(这里默认是),然后调用函数进行决策,通过TinyLFU算法来判断当前item是否值得被接受,以及如果接受之后超出内存上限需要通过 Sampled LFU 算法决定要淘汰哪些数据。如果值得添加,就调用函数将item添加到底层map中并记录指标,然后记录当前key的时间戳,方便后续计算寿命。如果不值得添加,就调用 onReject 回调函数,直接丢弃。然后对需要淘汰的数据进行删除。
更新操作
同理从setbuff中获取,未进入setbuff的添加的item参考添加操作。外部暴露的函数与添加操作一致,都是Set。进入setbuff的flag为更新操作的item仅更新相关指标即可。
删除操作
同理从setbuff中获取(有序队列,避免了先执行删除后又被恢复的场景),执行相关的指标更新,然后从底层删除,并调用相关的回调函数。
获取操作
先获取key的两个hash值,在从map寻找数据之前,会先执行一个Push操作,将访问计数的采集推入缓冲再进行读取,缓冲是自定义的一个ring-buffer,内部有sync.pool字段存储获取的key的切片,目的是合成批量操作降低开销。然后才会在真正的分片hash中查找对应的数据, 如果传入了 conflictHash 且不匹配就认为不存在,检查 item 是否过期(TTL),如果过期也当作不存在。
淘汰策略
采用的是 Sampled LFU(随机采样找出最不常用的候选)淘汰算法,当添加时发现空间不足时会先用 TinyLFU 估算新key的频率,然后从已有的item中随机抽取5个(源码写死,研究表明,5 个样本的概率足以近似全局最低频项)估算key的频率,如果新key最低,就不值得进入缓存,不是最低就将要淘汰的key添加到相关队列中,重复上述步骤,直到能把新key放进去。
总结
| 对比 | 数据类型限制 | 淘汰策略 | 一致性 | 过期设置 | GC | 内存利用率 | 适用场景 |
|---|---|---|---|---|---|---|---|
| bigcache | value 必须是 []byte |
FIFO | 强一致性 | 仅支持 全局过期时间,不支持单个 key 设置过期;获取时若过期按成功处理 | 0 GC | 支持动态扩展,利用率较高,但没有淘汰策略,过期数据可能占用内存较久 | 数据生命周期短,不太在意命中率;适合 短时缓存、临时存储 |
| freecache | key 和 value 都必须是 []byte |
Nearly LRU(近似 LRU) | 强一致性 | 支持 单个 key 设置过期时间;获取时若过期按失败处理 | 0 GC | 内存固定分配,利用率高;但 key 小 value 大 时可能产生空间碎片 | 命中率要求不高;适合 日志、监控指标等大量 KV 缓存 |
| ristretto | 无限制 | Sampled LFU(随机采样选出最不常用候选) | 最终一致性 | 支持 单个 key 设置过期时间;获取时若过期按失败处理 | Go GC | 有容量上限且控制精细,结合淘汰策略,整体 内存利用率最高 | 需要 高命中率;适合 业务缓存(用户会话、推荐系统、热点数据) |